Text analytics & topic modelling on music genres song lyrics
Jun 24, 2018 00:00 · 928 words · 5 minute read
This analysis uses a dataset of more than 380,000 songs since 1970 published in kaggle. The main objective is to develop clusters of music genres by the song lyrics and the steps are the following:
- Data preparation (cleansing, transform etc.)
- Exploratory analysis
- Topic modelling
Various R libraries were used, but it is mainly based on #tidytext and #tidyverse environment.
Data preparation was a very important part of the analysis. The first
step was to exclude all songs, where the text field of lyrics was less than 10
characters long.
Then, after looking at the lyrics text field, it seems that there were a lot
of non-English songs. The decision was to include only English
language songs in the final dataset. So, by using the cld3 library, the
origin of the songs was detected & added to the dataset. The language detection wasn’t perfect, as it
misclassified a few songs. But because of the large original dataset, i
decided to use it and remove all non-English songs from the dataset.
Finally all songs that music genre was either missing or unknown were removed.
Also all songs with invalid year input (less than 1970) were removed.
More details about these steps can be found, in the actual code, at the end of the article.
MAIN ANALYSIS
Below there is a statistical table and a frequency plot to indicate the differences between the music genres.
| Genre | Total songs | Proportion(%) |
|---|---|---|
| Rock | 99845 | 42.38 |
| Pop | 34291 | 14.56 |
| Hip-Hop | 22776 | 9.67 |
| Metal | 21181 | 8.99 |
| Not Available | 17265 | 7.33 |
| Country | 14227 | 6.04 |
| Jazz | 7322 | 3.11 |
| Electronic | 6778 | 2.88 |
| Other | 3908 | 1.66 |
| R&B | 3343 | 1.42 |
| Indie | 2957 | 1.26 |
| Folk | 1695 | 0.72 |
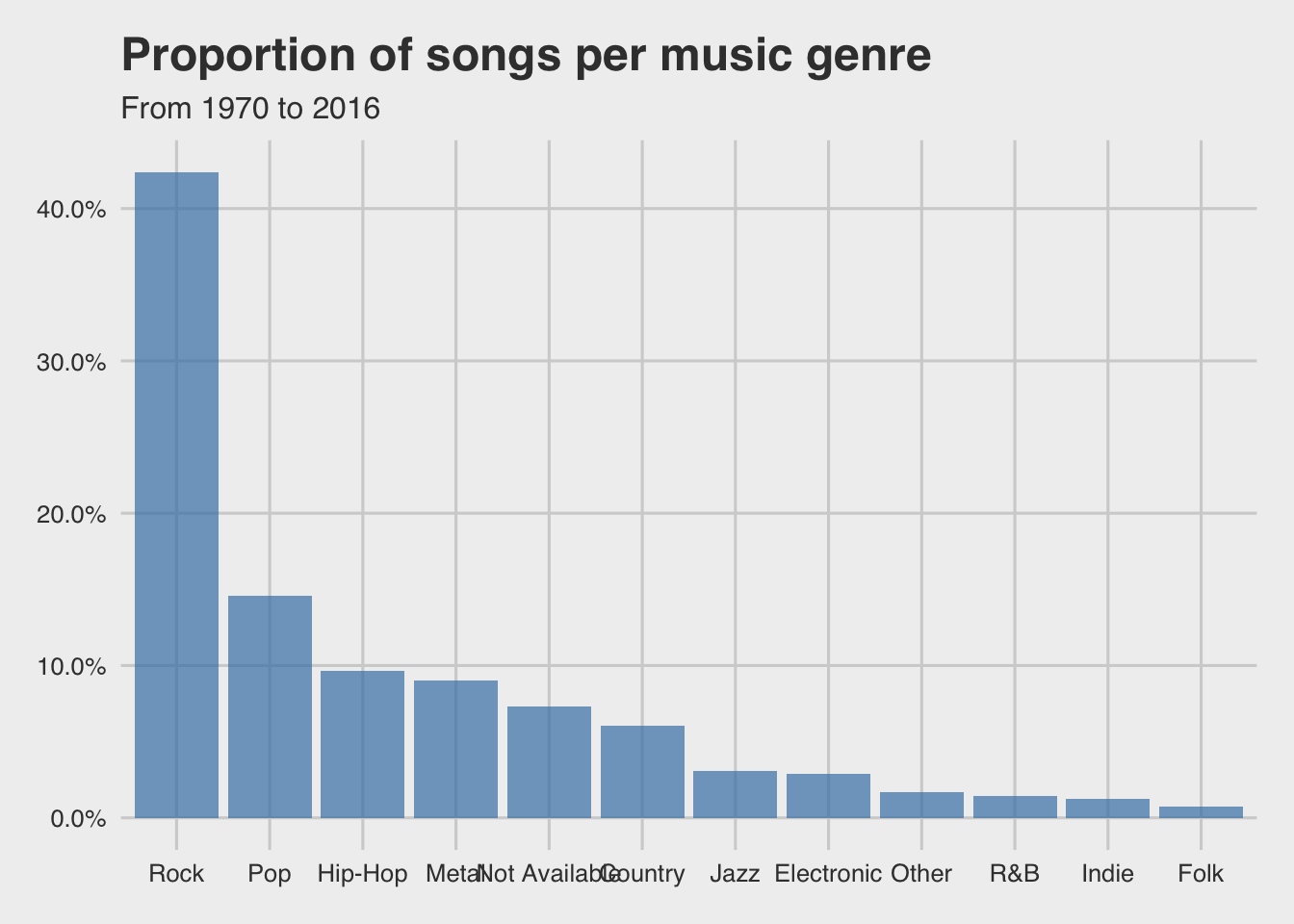
Most songs belong to the Rock genre, almost 50% of all songs in this dataset. The top 5 music genres are Rock, Pop, Hip-Hop, Metal & Country.
It would be interesting to see if this is constant through time, or not. Below there is a plot indicates the variation through years.
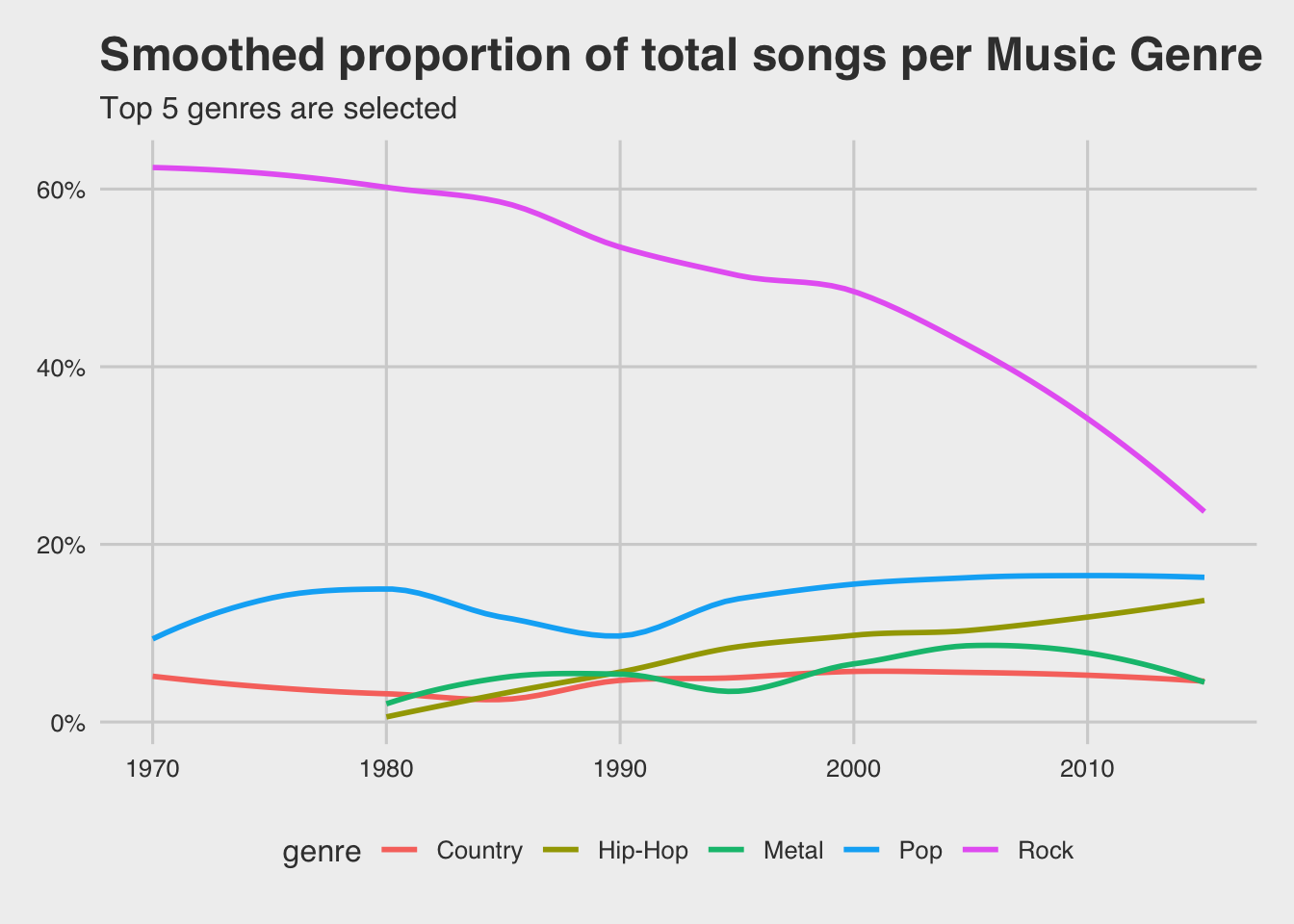
There are a few findings here. At first Rock genre decreases (from 60 % to 25 %) in overall proportion of songs. On the other hand, hip-hop gradually rises (currently near to 20 %). Pop is around to 20 % and fairly steady through years.
Now let’s try to figure out which music genre uses more lyrics.
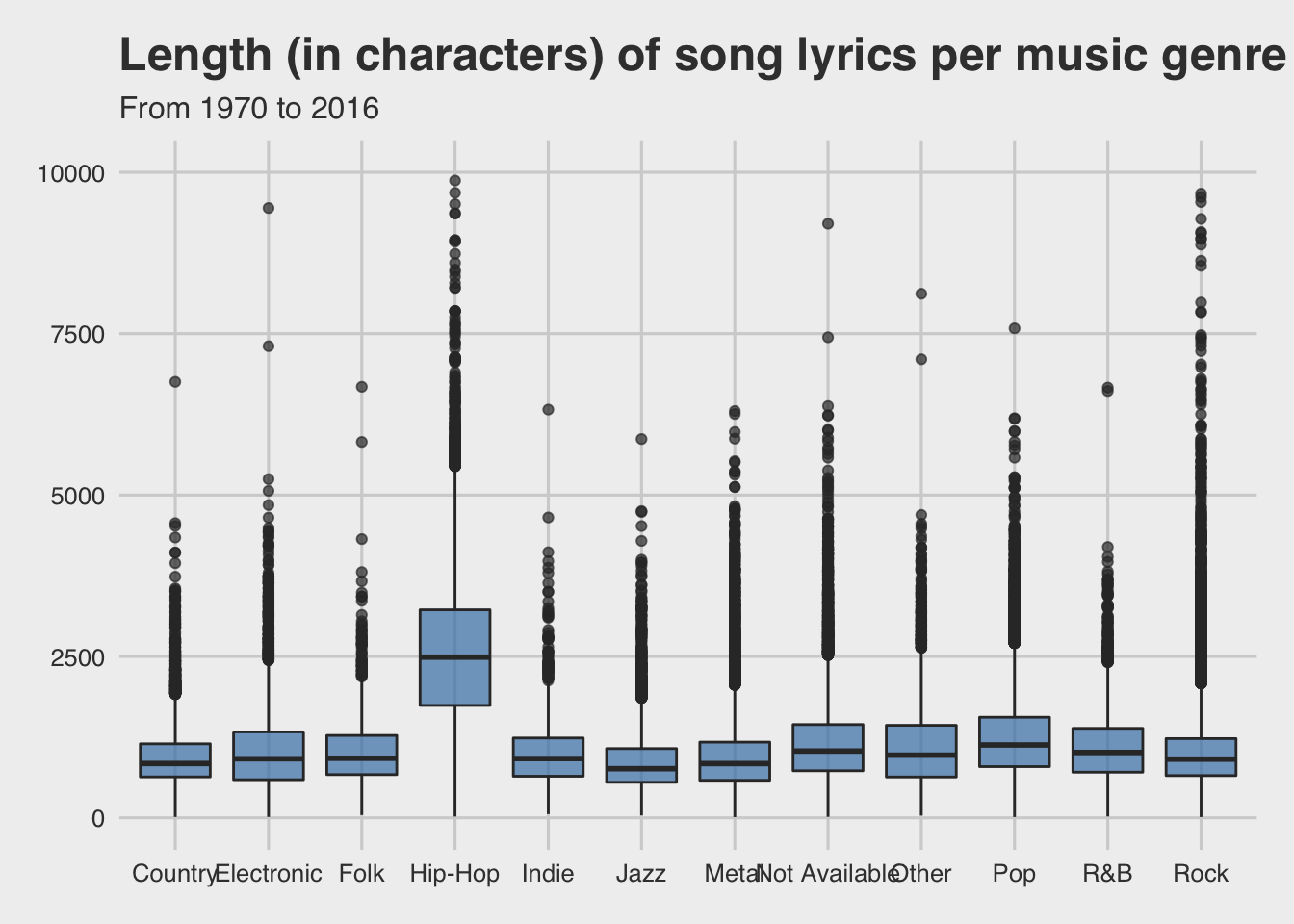
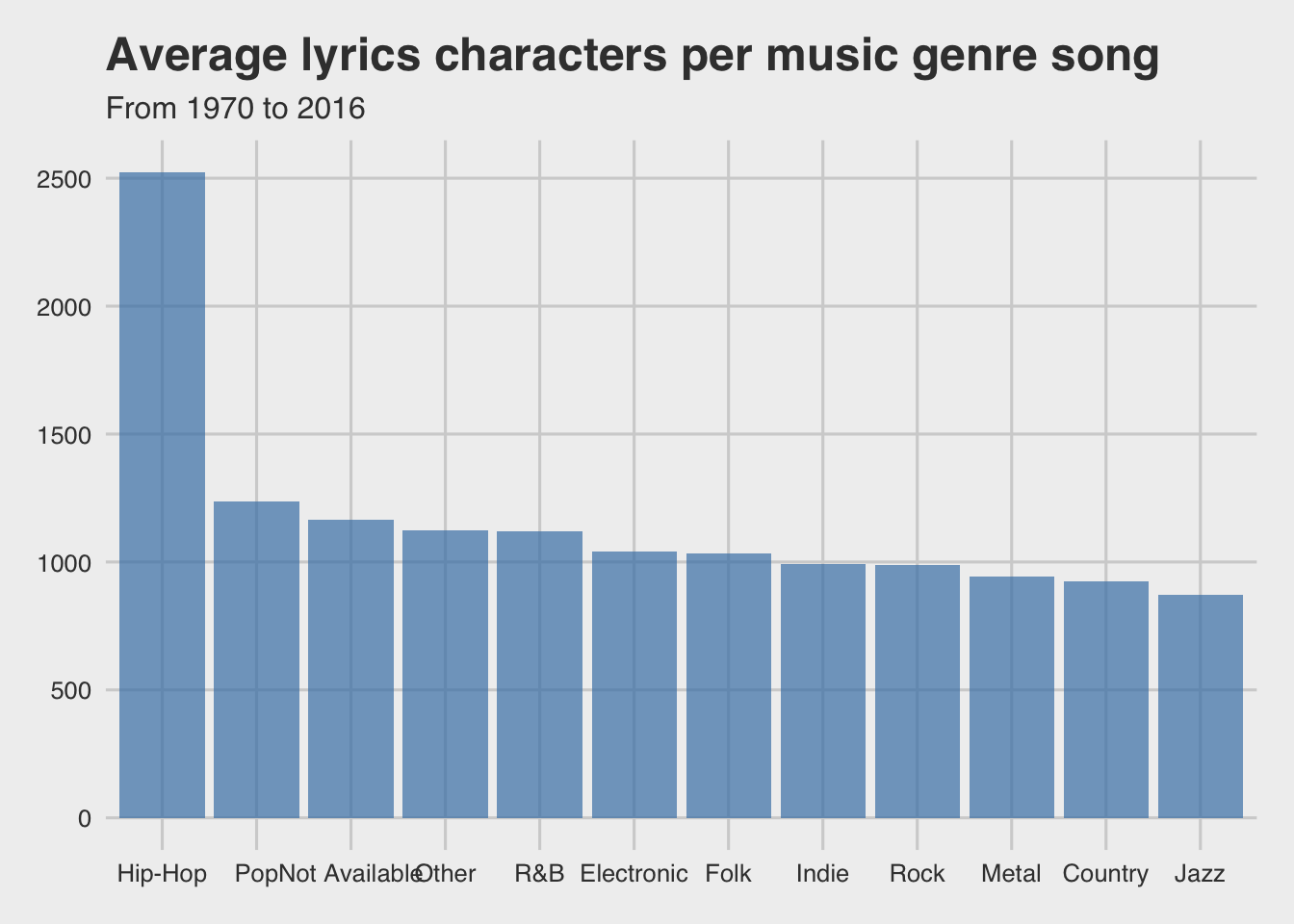
Hip-Hop seems to be a significantly different music genre, as it uses more than double lyrics per song than the rest of the genres.
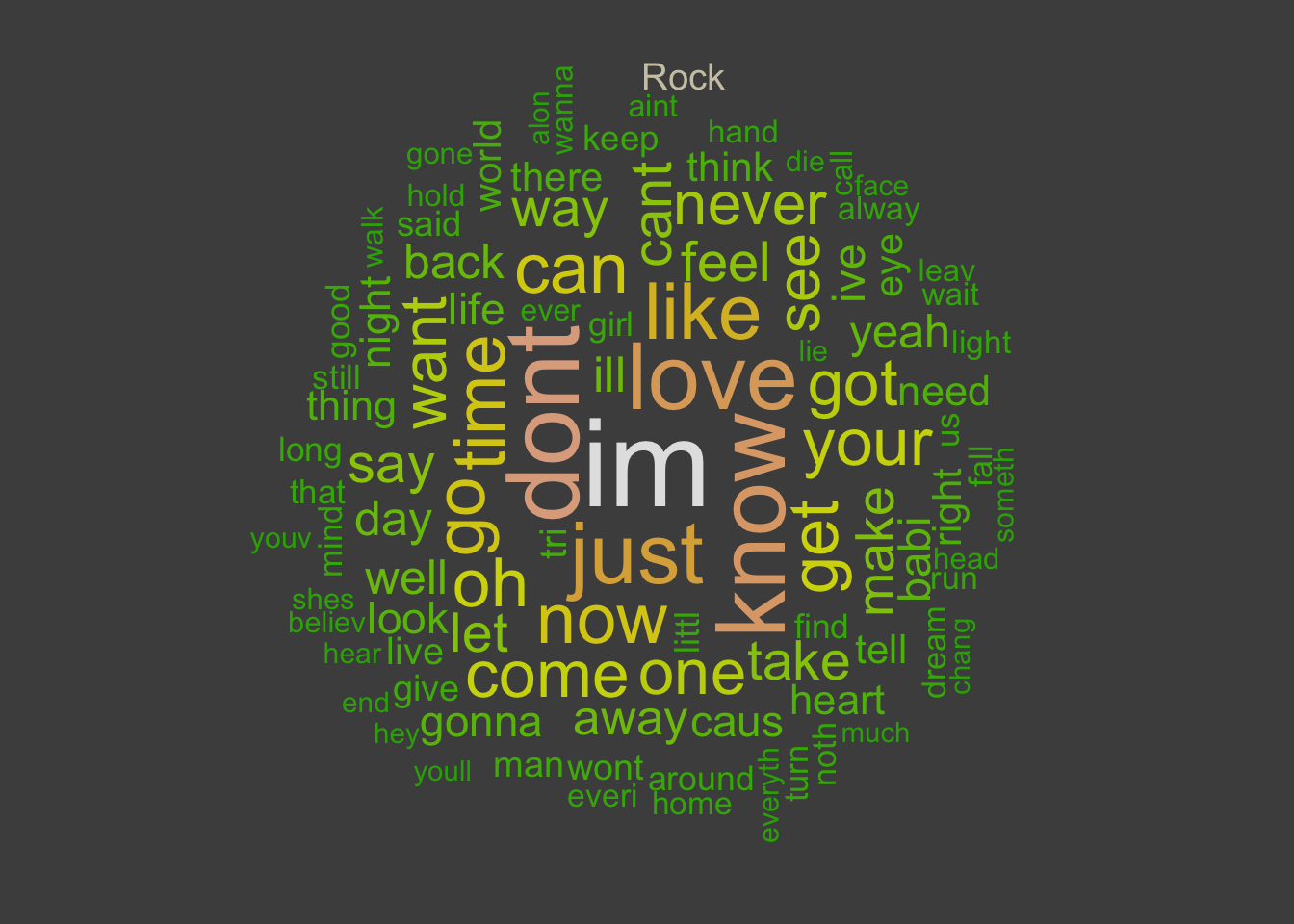
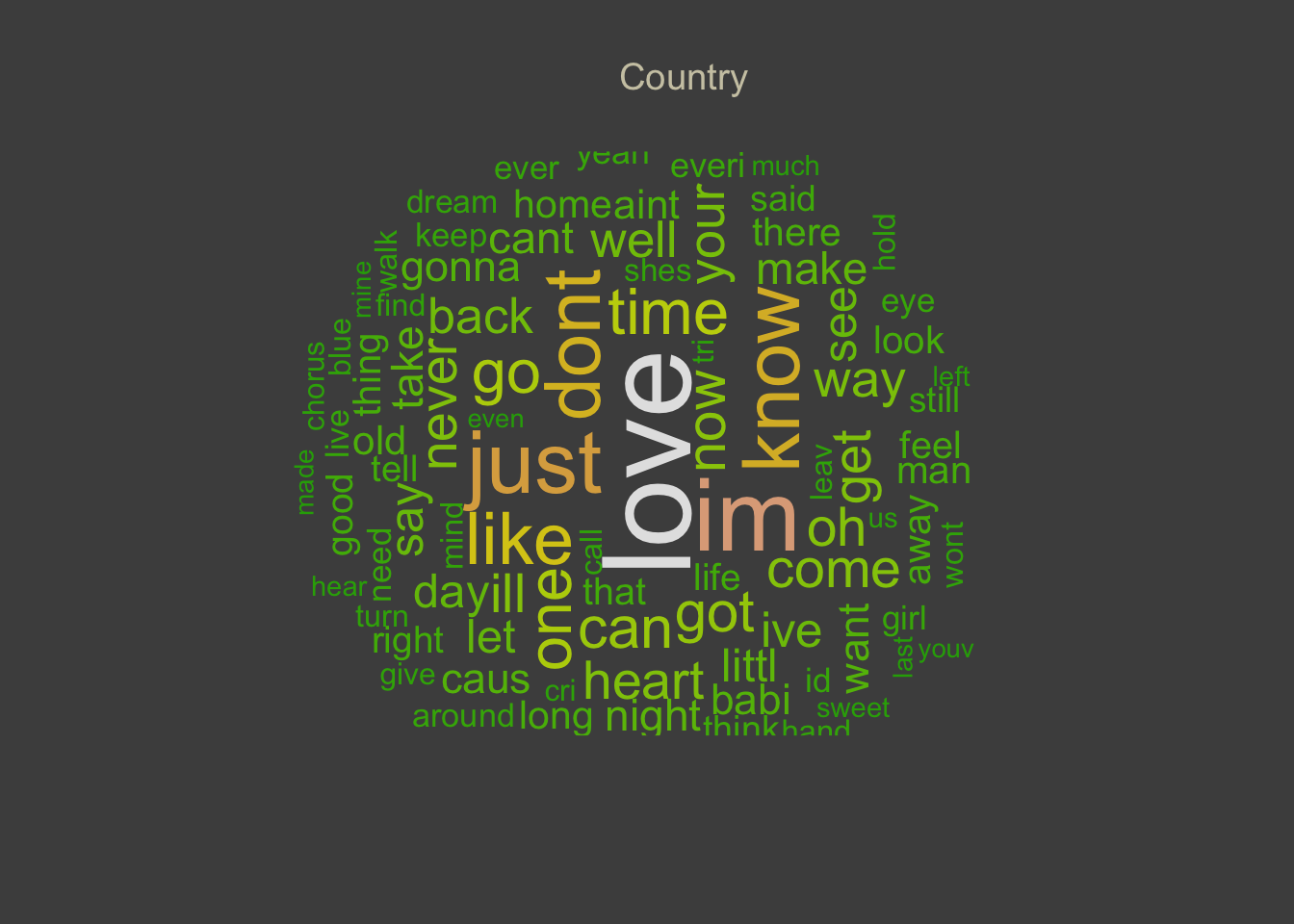
WORDCLOUD
It is interesting to see which are the most used words in each music genre.
Below there are word clouds for the top 5 music genres.
Word clouds (also known as text clouds or tag clouds) work in a simple way:
the more a specific word appears in a source of textual data, the bigger
and bolder it appears in the word cloud.
Below there are word clouds for the top 5 music genres.

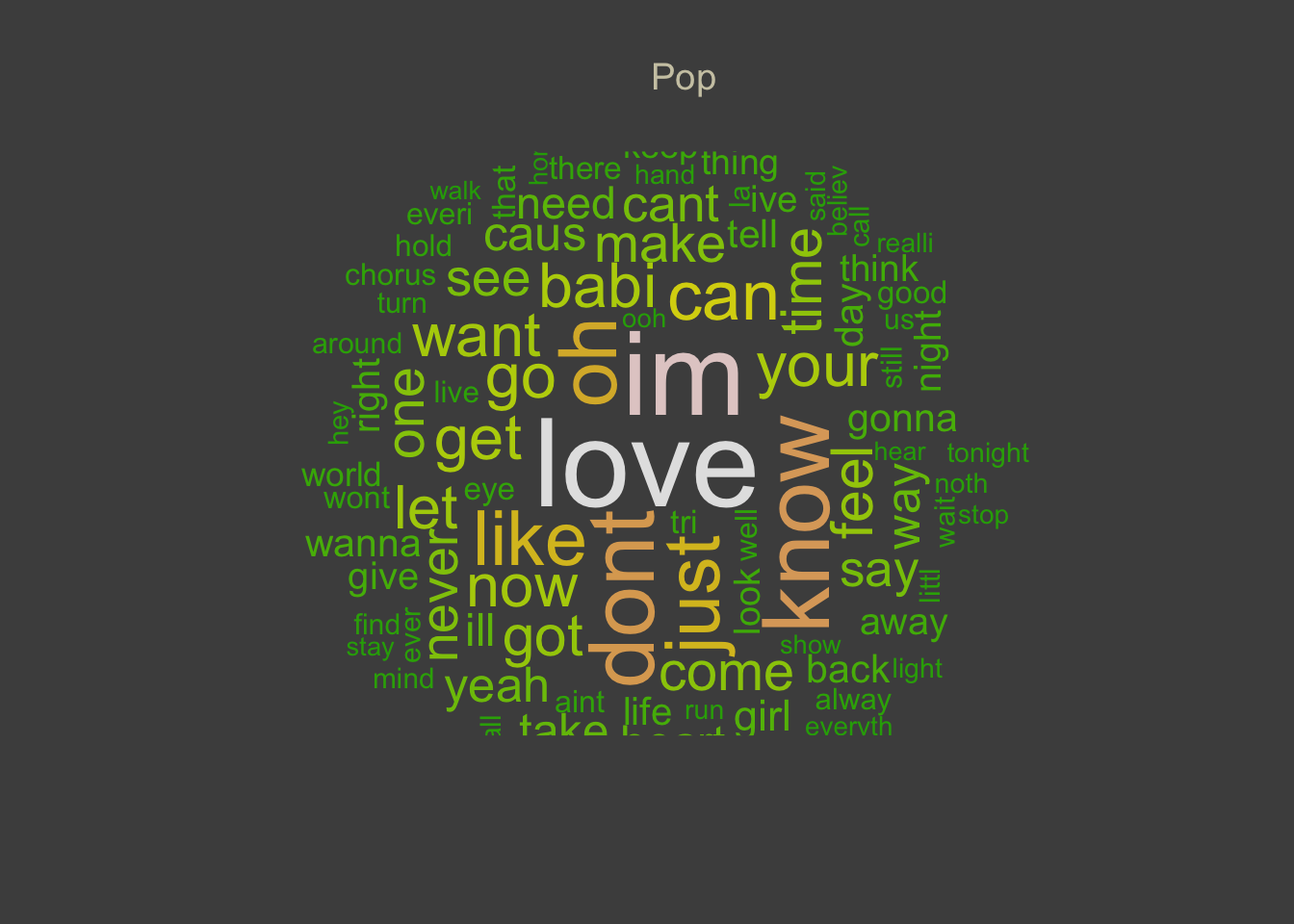

TOPIC MODELLING
Consider, for example, a situation in which you are confronted with a large collection of documents but have no idea what they are about. One of the first things you might want to do is to classify these documents into topics or themes. Among other things this would help you figure out if there’s anything interest while also directing you to the relevant subsets of the corpus. For small collections, one could do this by simply going through each document but this is clearly unfeasible for corpuses containing thousands of documents.
Topic modeling deals with the problem of automatically classifying sets of documents into themes. The algorithm chosen is Latent Dirichlet Allocation or LDA, which essentially is a technique that facilitates the automatic discovery of themes in a collection of documents.
The basic assumption behind LDA is that each of the documents in a collection consist of a mixture of collection-wide topics. However, in reality we observe only documents and words, not topics – the latter are part of the hidden (or latent) structure of documents. The aim is to infer the latent topic structure given the words and document. LDA does this by recreating the documents in the corpus by adjusting the relative importance of topics in documents and words in topics iteratively.
In our case an LDA model with two topics was developed. After computing the topic
probabilities for all songs, we can see if this unsupervised learning, distinguish
or reveal associations between music genres (regarding their lyrics).
The box-plot below, reveals the probabilities of each music genre song to belong
in each of the three topics.
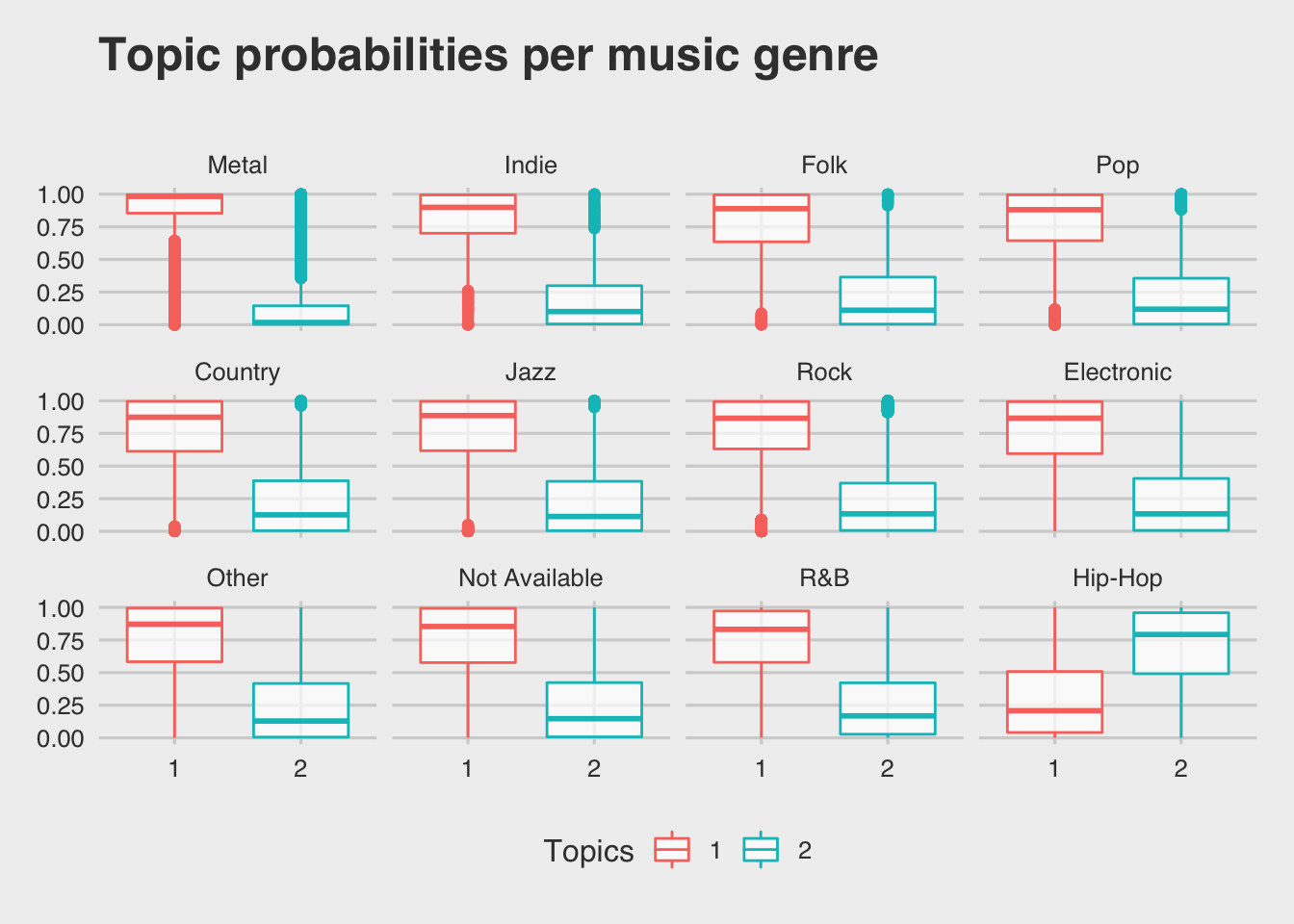
Hip-Hop genre is almost uniquely identified as a single topic (topic 2).
The rest of the music genres seem to be identified as another topic.
So we can say that Hip-Hop is definetely a music genre that uses significantly different language
in the lyrics than the rest of the genres.
More LDA models were developed (three & four topics) but the outcome of the initial
model (two topics) was more relevant and significant.
CONCLUSION
Finally we can conclude that:
- There is one music genre, Hip-hop, that is significantly different than
the rest of the genres, as it uses much more & different lyrics.
- Rock genre is gradually decreases in popularity through years, by including less
songs and new genres are emerging.
HARDWARE ENVIRONMENT
All tasks of the analysis were accomplished on a laptop with 8 GB RAM & Intel
Core I5 2.1 GHz. Some of the tasks can be demanding (for large datasets with
text data). e.g. the LDA modelling task took around 7-8 minutes to complete.